이전에 Headless Chrome의 사용방법에 관한 글을 올리고 Chrome의 headless_shell을 직접 컴파일해서 사용하는 방법에 대해서도 올렸다.(이 글이 6월이었다니...)
이전 글에서도 얘기했듯이 headless_shell을 테스트해보는 이유는 AWS Lambda에서 사용해보기 위함이다. AWS Lambda에서 사용할 수 있으면 다른 환경에서는 훨씬 쉽게 사용할 수 있고 Headless Chrome 같은 경우 자동화에 활용할 가능성이 크므로 Lambda 같은데 올려서 쓸 수 있다면 제격이라고 생각했다. Chrome 버전이 계속 올라가긴 하겠지만 현재 Headless Chrome으로 어디까지 할 수 있고 어떻게 활용할 수 있는지 파악해 놓고자 함이었다.
웹페이지 스크린샷
Internet Archive Wayback Machine처럼 내가 원하는 사이트를 정기적으로 계속 스크린샷을 찍으려고 한다. 요즘은 잘 안 바꾸지만 내 블로그의 디자인을 변경하는 때도 있으므로 예전부터 로컬에서 스크린샷을 찍어서 보관하고 있었다. 로컬에서 돌리는 건 아무래도 환경마다 달라서 귀찮으므로 이를 Labmda에 올려서 알아서 돌아가게 하면 좋겠다는 생각을 했다. 뭐 이전에도 이런 작업은 충분히 가능했지만 귀찮아서 놔두다가 Headless Chrome을 사용해 보기 좋아서 선택했다.
물론 이는 사이트에 접속해서 스크린샷만 찍는 것이므로 브라우저의 동작까지 제어해야 하는 자동화보다는 훨씬 간단한 작업이지만 Lambda에서 Headless Chrome을 돌려보기에는 적당한 주제라고 생각했다.(기대보다 훨씬 험난했지만...)
이렇게 작성한 Lambda 함수는 GitHub에 올려두었지만이 글 이후에도 소스를 계속 수정할 것 같으므로 여기서는 만들면서 겪은 이슈 위주로 정리해 보려고 한다. Lambda를 쓸 때 apex를 사용하고 있지만, 이 글에서는 설명이 복잡하므로 따로 만들어서 직접 Lambda에 업로드 하려고 한다.
스크린샷 Lambda
AWS Lambda에 올릴 Node.js 코드를 예시로 작성할 예정이고 환경은 Node.js 6.10을 사용할 것이다.
Chrome Launcher
크롬을 사용할 것이므로 일단 크롬을 실행해야 하는데 나는 chrome-launcher를 선택했다. 쉘 명령어로 직접 headless_shell을 실행해도 되지만 이경우 관리가 좀 귀찮을 것으로 생각했고 구글 크롬에서 관리하는 Lighthouse 아래 있는 chrome-launcher가 사용하기 적당해 보였다.
관련해서 몇 가지 참고할 부분이 있는데
- 현재 0.6.0 인데 0.4.0 이전까지는 Lighthouse와 같이 배포되었으므로
require('lighthouse/lighthouse-cli/chrome-launcher')처럼 가져와야 했지만, 이제는 별도의 npm 모듈로 배포되므로 바로 require('chrome-launcher')로 가져오면 된다. 0.4.0 이전 버전을 사용하는 글을 참고한다면 참고해야 한다. - 구글 크롬팀에서
chrome-launcher외에 Headless Chrome을 Node.js로 제어할 수 있는 Puppeteer을 얼마 전에 공개했다. 이번에 만든 Lambda도 Puppeteer으로 변경할 예정이긴 하지만 아직 사용해보지 않았다. 새로 시작한다면 Puppeteer으로 바로 시작하는 게 더 좋을 수도 있다.
현재 chrome-launcher버전은 0.6.0이다. 이제 Headless Chrome을 사용할 코드를 작성하기 위해서 chrome.js을 다음과 같이 만든다. 경험상 Lambda를 쓸 때 위의 index.js는 아주 간단하게만 둔 채로 다른 로직은 별도의 파일로 작성하는 게 테스트도 작성하기 쉽고 훨씬 낫다. 먼저 chrome-launcher를 설치하고(npm install chrome-launcher) chrome.js에 다음과 같은 코드를 작성한다. 현재 버전은 0.6.0이다.
// chrome.js
const chromeLauncher = require('chrome-launcher');
const launchChrome = () => {
return chromeLauncher.launch({
chromeFlags: [
'--headless',
'--disable-gpu',
'--no-sandbox',
'--vmodule',
'--single-process',
],
logLevel: 'verbose',
})
.then((chrome) => {
console.log(`Headless Chrome launched with debugging port ${chrome.port}`);
return chrome;
});
};
launchChrome();
간단히 chromeLauncher.launch()로 원하는 플래그와 옵션을 지정해서 크롬을 실행하는 코드이다.
chromeFlags은 크롬에 직접 전달하는 플래그이다. chromeLauncher에서 지원하지 않는 옵션은 이렇게 지정해야 한다.
--headless은 Headless 모드로 띄우기 위해 실행했다.--disable-gpu는 GPU의 사용을 끈 것이다. 문서에 따르면 Mesa 라이브러리가 없는 경우 오류를 피하려면 필요하다는데 내 테스트에서는 없어도 큰 문제는 없었다. 일단 문서에 그렇게 나와 있으니 지정했다.--no-sandbox는 macOS에서는 괜찮았지만, Linux 환경(특히 Lambda)에 가면 이 옵션이 없으면 No usable sandbox!라는 오류가 발생하고 문서를 참고하라고 나온다.--vmodule과 --single-process는 좀 묘한 옵션인데 macOS와 로컬에서 Linux 환경에서도 다 괜찮았는데 Lambda에만 올리면 Headless Chrome을 정상적으로 띄웠음에도 chrome devtools protocol에 접속하지 못하는 문제가 생긴다. 좀 더 정확히는 크롬을 띄우고 chrome devtools protocol로 리스트를 요청하면 chrome devtools protocol에 접속 가능한 URL과 웹소켓 주소 등이 나와야 하는데 아무것도 주지 않는다. 크롬 버그인지 어떤지까지는 추적을 못 했지만 이 두 옵션을 지정하면 Lambda에서도 정상 동작한다.
logLevel은 런처의 로그 메시지 설정이다. 문제가 생길 때마다 디버깅을 해야 해서 verbose로 아예 켜두었다.
위 코드를 실행해보자.
$ node chrome.js
ChromeLauncher:verbose created /var/folders/k8/j1j0fjkn5_vdzxybfqq0r7lc0000gn/T/lighthouse.XXXXXXX.8tqw7dbE +0ms
ChromeLauncher:verbose Launching with command:
ChromeLauncher:verbose "/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary" --disable-translate --disable-extensions --disable-background-networking --safebrowsing-disable-auto-update --disable-sync --metrics-recording-only --disable-default-apps --mute-audio --no-first-run --remote-debugging-port=50069 --user-data-dir=/var/folders/k8/j1j0fjkn5_vdzxybfqq0r7lc0000gn/T/lighthouse.XXXXXXX.8tqw7dbE --headless --disable-gpu --no-sandbox --homedir=/tmp --data-path=/tmp/data-path --disk-cache-dir=/tmp/cache-dir --vmodule --single-process about:blank +588ms
ChromeLauncher:verbose Chrome running with pid 7834 on port 50069. +4ms
ChromeLauncher Waiting for browser. +1ms
ChromeLauncher Waiting for browser... +0ms
ChromeLauncher Waiting for browser..... +511ms
ChromeLauncher Waiting for browser.....✓ +3ms
Headless Chrome launched with debugging port 50069
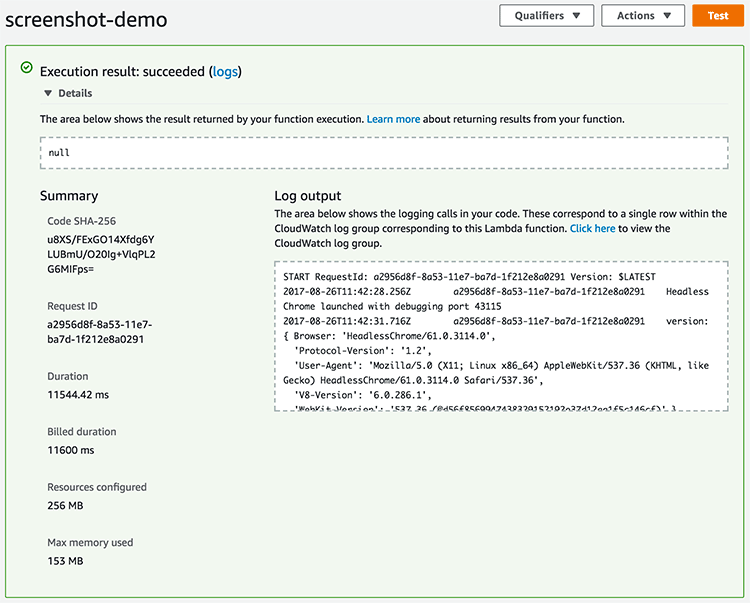
로그를 켜두었으므로 실행과정을 볼 수 있는데 정상적으로 Headless Chrome이 뜬 것을 볼 수 있다. --remote-debugging-port의 기본 포트는 9222인데 여기서는 지정하지 않았으므로 동적으로 할당해서 사용한다. 크롬이 실행되면서 반환한 객체는 { pid: 5891, port: 62993, kill: [Function: kill] }처럼 생겼다. 프로세스의 pid와 디버깅 포트 정보가 있고 실행한 크롬을 죽일 수 있는 kill()함수가 있다.
headless_shell
chrome-launcher는 설치된 크롬을 자동으로 찾는다. Chrome Canary가 설치되어 있다면 이를 먼저 사용하고 아니면 Chrome을 찾는다.
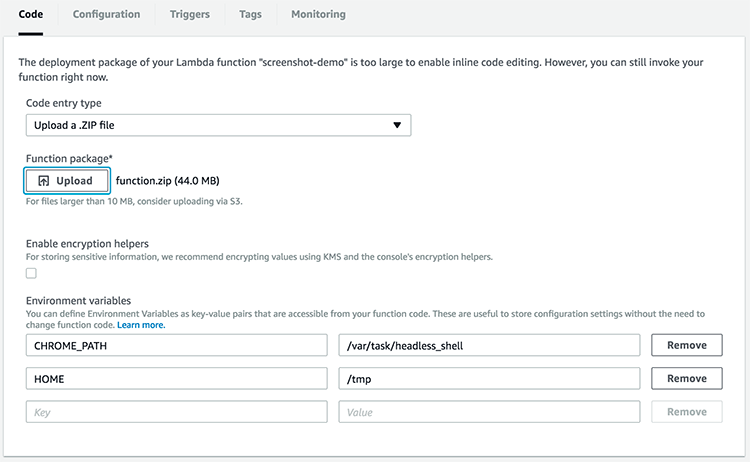
사용 중인 데스크톱에는 보통 크롬이 설치되어 있겠지만 서버의 경우는 다르다. 나 같은 경우도 서버, 여기서는 AWS Lambda를 사용하기 위해서 headless_shell만 별도로 컴파일했다. 이렇게 별도로 있는 크롬 바이너리를 실행하려면 CHROME_PATH로 환경 변수로 크롬의 위치를 지정해 주어야 한다.
AWS Lambda라면 코드를 업로드 했을 때 /var/task에 올려지므로 업로드하는 코드에 headless_shell을 포함한다면 CHROME_PATH=/var/task/headless_shell로 환경변수를 지정해야 Lambda 내에서도 chrome-launcher가 정상적으로 크롬을 찾아낸다. 물론 환경변수보다 OS 설치된 크롬을 먼저 찾는다.
참고삼아 얘기하지만, chrome-launcher 0.4.0 이전 버전에서는 LIGHTHOUSE_CHROMIUM_PATH환경변수를 사용했는데 지금은 CHROME_PATH로 바뀌었다.
Chrome Devtools Protocol
크롬에는 Chrome DevTools Protocol이 있다. 이는 크롬에서 개발자도구로 웹사이트를 디버깅, 프로파일링, 검사하듯이 원격에서 이 프로토콜을 사용하면 크롬으로 똑같은 일을 할 수 있다. 많은 도구가 이 프로토콜을 이용하고 있다.
이 프로토콜의 동작을 확인해보자.
macOS에서 bash를 쓴다면 설치된 크롬 카나리를 터미널에서 실행할 수 있도록 다음과 같이 별칭을 준다.
$ alias chrome-canary="/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary"
$ chrome-canary \
--headless --disable-gpu \
--remote-debugging-port=9222
[0824/223949.914930:WARNING:dns_config_service_posix.cc(156)] dns_config has unhandled options!
DevTools listening on ws://127.0.0.1:9222/devtools/browser/a2c2fe73-a8bc-49c8-84aa-61a251a7def9
헤드리스 모드로 크롬 카나리를 실행하고 원격 디버깅 포트를 9222로 실행하자 개발자 도구가 9222 포트를 리스닝하고 있는 것을 볼 수 있다. 이렇게 실행해 놓은 채로 터미널을 하나 더 열어서 이 디버깅 포트에 요청을 보내보자.
$ curl http://localhost:9222/json/version
{
"Browser": "HeadlessChrome/62.0.3194.0",
"Protocol-Version": "1.2",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/62.0.3194.0 Safari/537.36",
"V8-Version": "6.2.333",
"WebKit-Version": "537.36 (@c14400a94cb4f43e0e9b02e59e93cf5a082c6408)",
"webSocketDebuggerUrl": "ws://localhost:9222/devtools/browser/a2c2fe73-a8bc-49c8-84aa-61a251a7def9"
}
$ curl http://localhost:9222/json/list
[ {
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9222/devtools/page/e873e5cb-f1db-4892-87cf-5296fbc7485c",
"id": "e873e5cb-f1db-4892-87cf-5296fbc7485c",
"title": "about:blank",
"type": "page",
"url": "about:blank",
"webSocketDebuggerUrl": "ws://localhost:9222/devtools/page/e873e5cb-f1db-4892-87cf-5296fbc7485c"
} ]
/json/version으로 요청을 보내면 현재 크롬의 정보를 볼 수 있고 /json/list를 이용하면 접속할 수 있는 Chrome Devtools Protocol 목록을 반환한다. 목록이 배열인 이유는 크롬에서 탭을 여러 개 열 수도 있기 때문이다. 각 클라이언트는 이 정보 등을 이용해서 Chrome Devtools Protocol을 구현하고 프로토콜에서 제공하는 객체로 크롬을 제어할 수 있다. DOM, Page, Network 등 세세하게 다룰 수 있게 모두 제공하는데 직접 클라이언트를 개발하는 게 아니라면 세부 내용을 다 알 필요는 없어 보인다. 필요할 때 위 문서를 참고해보는 정도로 충분하다.
chrome-remote-interface
Chrome DevTools Protocol을 직접 사용하는 것은 어려우므로 이미 존재하는 많은 라이브러리가 존재하는데 공식 문서에서 권장하는 chrome-remote-interface를 사용했다.
chrome-remote-interface를 설치하고(npm install chrome-remote-interface) 앞에서 작성한 launchChrome()를 이용해서 Chrome Devtools Protocol에 연결해보자. 현재 버전은 0.24.4다.
// chrome.js
const CDP = require('chrome-remote-interface');
// launchChrome 부분 생략
let launchedChrome = null;
const connectChrome = () => {
return launchChrome()
.then((chrome) => {
launchedChrome = chrome;
return CDP.Version({ port: launchedChrome.port });
})
.then(info => console.log('version: ', info))
.then(() => CDP({ port: launchedChrome.port }))
.then((client) => {
console.log('client connected');
});
};
connectChrome();
이를 실행하면 다음과 같이 실행된 크롬에 접속해서 정보를 가져오고(CDP.Version) 연결을 하는 것을 볼 수 잇다. 여기서 CDP({ port: launchedChrome.port }))에서 포트만 지정했는데 host를 지정하지 않으면 localhost를 사용한다.
node chrome.js
ChromeLauncher:verbose created /var/folders/k8/j1j0fjkn5_vdzxybfqq0r7lc0000gn/T/lighthouse.XXXXXXX.rNE9ehBV +0ms
ChromeLauncher:verbose Launching with command:
ChromeLauncher:verbose "/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary" --disable-translate --disable-extensions --disable-background-networking --safebrowsing-disable-auto-update --disable-sync --metrics-recording-only --disable-default-apps --mute-audio --no-first-run --remote-debugging-port=64165 --user-data-dir=/var/folders/k8/j1j0fjkn5_vdzxybfqq0r7lc0000gn/T/lighthouse.XXXXXXX.rNE9ehBV --headless --disable-gpu --no-sandbox --homedir=/tmp --data-path=/tmp/data-path --disk-cache-dir=/tmp/cache-dir --vmodule --single-process about:blank +528ms
ChromeLauncher:verbose Chrome running with pid 29094 on port 64165. +16ms
ChromeLauncher Waiting for browser. +0ms
ChromeLauncher Waiting for browser... +0ms
ChromeLauncher Waiting for browser..... +512ms
ChromeLauncher Waiting for browser.....✓ +2ms
Headless Chrome launched with debugging port 64165
version: { Browser: 'HeadlessChrome/62.0.3196.0',
'Protocol-Version': '1.2',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/62.0.3196.0 Safari/537.36',
'V8-Version': '6.2.363',
'WebKit-Version': '537.36 (@1bdf82f83c51a1f42672bc8e59494d238269fc6f)',
webSocketDebuggerUrl: 'ws://localhost:64165/devtools/browser/87f5f38e-cae0-43c2-b595-d199d2c73d86' }
client connected
여기서 CDP({ port: launchedChrome.port }))가 반환한 client객체는 Chrome DevTools Protocol에 있는 Page, Memory, Inspector, CSS, CacheStorage같은 객체가 있으므로 이를 이용해서 크롬을 조작하면 된다.
웹사이트 스크린샷 찍기
이제 준비가 다 되었으니 chrome-remote-interface를 이용해서 스크린샷을 찍을 차례다.
// chrome.js
const chromeLauncher = require('chrome-launcher');
const CDP = require('chrome-remote-interface');
// launchChrome 부분 생략
const connectChrome = () => {
return launchChrome()
.then((chrome) => {
launchedChrome = chrome;
return CDP.Version({ port: launchedChrome.port });
})
.then(info => console.log('version: ', info))
.then(() => CDP({ port: launchedChrome.port }))
.then((client) => {
console.log('client connected');
const { DOM, Emulation, Network, Page } = client;
return Page.enable()
.then(DOM.enable)
.then(Network.enable)
.then(() => {
const deviceMetrics = {
width: 1280,
height: 1000,
deviceScaleFactor: 0,
mobile: false,
fitWindow: false,
};
return Emulation.setDeviceMetricsOverride(deviceMetrics);
})
.then(() => Page.navigate({ url: 'https://github.com' }))
.then(Page.loadEventFired)
.then(() => Emulation.setVisibleSize({ width: 1280, height: 1000 }))
.then(Page.captureScreenshot)
.then(screenshot => new Buffer(screenshot.data, 'base64'))
.catch((err) => {
client.close();
throw err;
});
})
.catch((err) => {
console.log(err);
launchedChrome.kill();
throw err;
});
};
module.exports = {
connectChrome,
};
위 코드가 CDP로 웹페이지를 띄워서 페이지 로딩이 끝나면 스크린샷을 찍어서 Buffer를 반환하는 코드이다. 간단히 설명하자면...
const { DOM, Emulation, Network, Page } = client;는 클라이언트에서 사용할 객체만 가져왔다.Page.enable()에서 페이지를 활성화한다.DOM.enable에서 해당 페이지에 DOM을 활성화한다.Network.enable에서 해당 페이지의 네트워크 활동을 추적할 수 있게 한다.Emulation.setDeviceMetricsOverride에서 디바이스의 스크린 설정을 지정한다. 여기서는 width, height를 지정하고(뒤에서 재지정한다.) 모바일 여부 등을 설정할 수 있는데 여기서는 특별한 설정은 하지 않았다.Page.navigate에서 지정한 URL로 페이지를 이동한다.Page.loadEventFired는 웹페이지에서 load이벤트가 발생하면 실행된다.Emulation.setVisibleSize에서는 스크린샷을 찍기 위해서 페이지의 viewport 크기를 지정한다. 문서를 보면 deprecated로 표시되고 있는데 chrome-remote-interface에서 아직 이 방법으로 안내하고 있어서 그대로 사용했다. 아직 다른 방법은 찾지 못했다.Page.captureScreenshot에서는 현재 페이지의 스크린샷을 찍는다.screenshot => new Buffer(screenshot.data, 'base64')에서는 Page.captureScreenshot가 반환한 base64데이터를 Buffer로 생성해서 반환한다.
참고로 스크린샷을 찍는 작업을 하면서 여러 웹사이트를 한 번에 찍으려고 할 때 매번 크롬을 띄우고 DevTools Protocol에 붙을 필요가 없으므로 한번 연결해 놓고 URL만 변경하면서 계속 스크린샷을 찍으려고 할 때 Emulation.setVisibleSize를 Page.loadEventFired이후에 하지 않으니까 처음 스크린샷만 지정한 사이즈로 찍히고 이후부터는 기본값인 800x600으로 찍히는 문제가 있었다. 이 문제가 Chrome의 버그인지 chrome-remote-interface의 버그인지는 아직 잘 모르겠다.
파일을 S3에 업로드하기
이 코드를 Lambda에서 실행할 것이므로 파일을 로컬에 저장할 수 없으므로 다른 스토리지에 저장해야 한다. 여기서는 S3에 저장하려고 아래와 같은 s3.js를 만들었다.
// s3.js
const AWS = require('aws-sdk');
const s3 = new AWS.S3({ apiVersion: '2006-03-01' });
module.exports = {
uploadFile: (buffer) => {
return new Promise((resolve, reject) => {
const params = {
Bucket: 'outsider-demo',
Key: 'screenshot.png',
Body: buffer,
};
return s3.putObject(params, (err) => {
if (err) { return reject(err); }
return resolve();
});
});
},
};
aws-sdk를 이용해서 전달받은 Buffer를 S3 버킷(여기서는 outsider-demo)에 저장하는 Promise 코드이다. 예시를 간단하게 하려고 파일명 등은 하드 코딩했다.
이 글은 Headless Chrome으로 AWS Lambda에서 웹사이트 스크린샷 찍기 #2로 이어진다.
댓글 쓰기
![]()